Redis中的很多结构也是和Java中应用的数据结构类似,以下是整理Redis看过的一些资料整理的笔记。供学习参考。
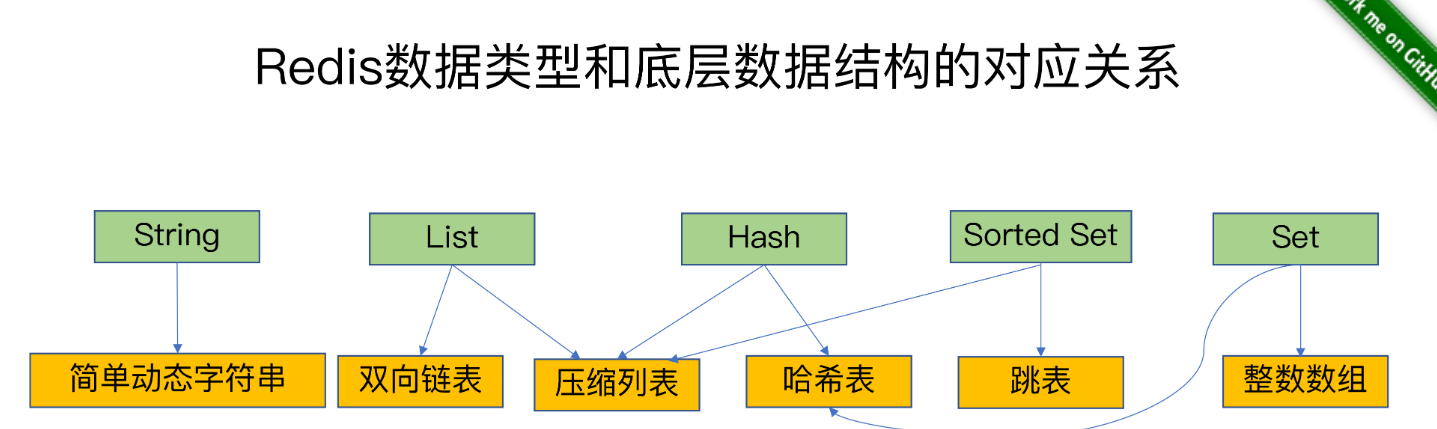
以下逐一梳理类型进行说明
String类型
是redis中最基本的类型,一个key对应一个value。类型是二进制安全的,redis的String可以包含任何数据。(SET和GET以及其他)。String采用简单动态字符串(simple dynamic string),简称SDS。作为Redis默认的字符串表示。Redis作为内存型数据库定位是追求性能,传统的C字符串不能满足苛刻的性能下的要求。
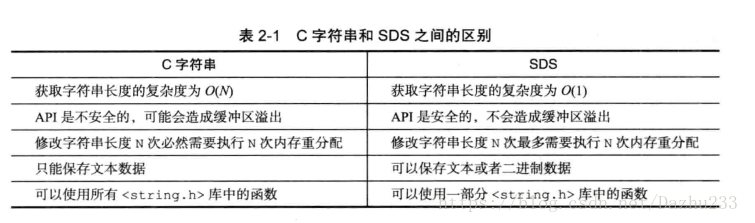
1)C语言中的C字符串不记录自身长度,在对字符串进行操作的时候容易带来缓冲区溢出。
2)减少因为修改字符串带来的内存重分配次数,C语言字符串在指向操作前需要通过内存重分配来扩展底层数组的空间大小。是一个比较耗时的操作。
在Redis中使用get和set命令即可。
SDS内存操作实现空间预分配和惰性空间是否的两种优化策略:
1)空间预分配
通过提前检查未使用的空间是否足够,通过该方式减少连续字符串增长所需要的内存重分配次数。
2)惰性空间释放
当SDS的API需要缩短SDS保存的字符串时,并不立即回收,而是把缩短后的长度记录在len属性中,剩余空间用于未来扩展字符串用。
Setbit的位操作
二进制的比特运算可以极大程度的节省空间,例如可以作为大用户量的是否登录统计,以及使用位运算进行用户量的或和与运算。
Setbit a 1 1
Setbit a 2 1
SETEX命令
SETEX是SET和EXPIRE的运算的组合,通过该命令实现原子性操作。可以在同一时间内完成设置值和设置过期时间操作。在用于缓存的时候非常实用。(设置的时间默认使用毫秒)
SETEX key seconds value
TTL Key(通过该方式查看key的剩余时间)
哈希类型
数据结构
是一个String类型的键值对集合,可以看作是Key、Value存储的MAP容器。
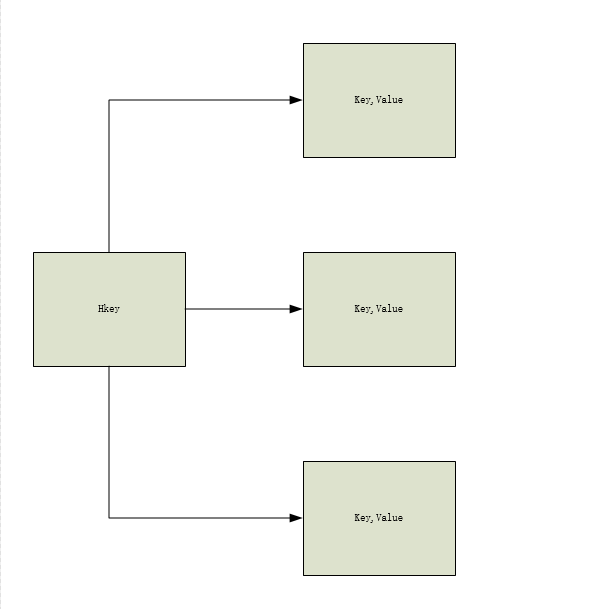
常见命令
HMSET:设置Key值的Key,Value键值对
HMGET:获得Key值对应的Key,Value键值对
HDEL:删除一个或多个指定Key值得字段
HSCAN:遍历迭代哈希表中的键值对
List类型
是一个双向链表,按照插入顺序排序的字符串列表,可以在列表的头部或者尾部添加元素,可以包含超过40亿个元素。可以充当栈或队列的角色。
数据结构
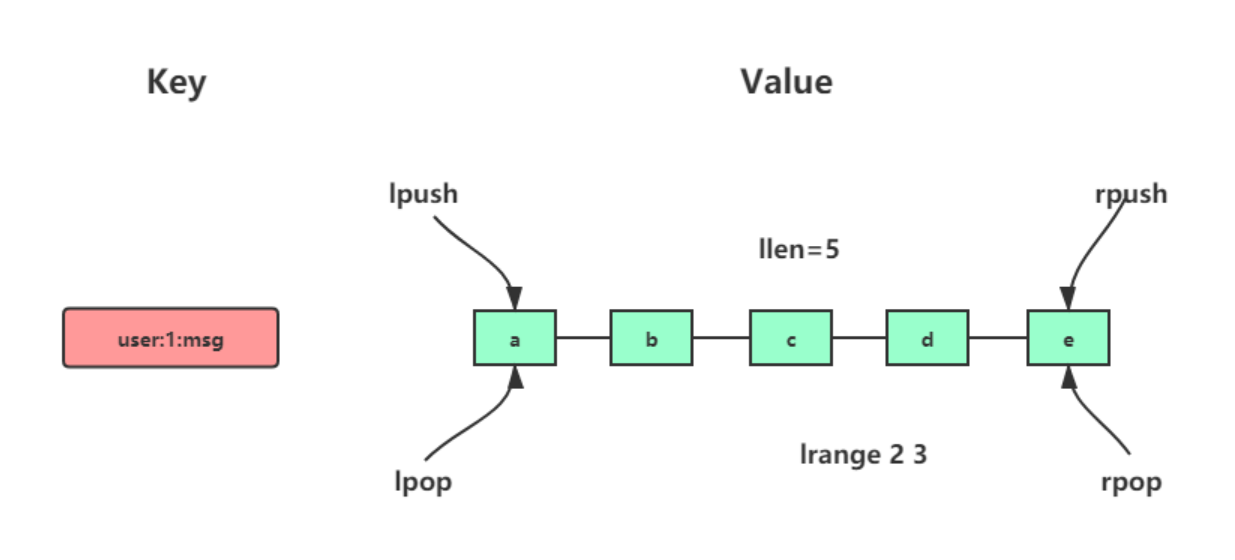
在Redis 3.2版本以前
1)当元素个数小于512个(默认情况),同时列表中每个元素的值都小于list-max-ziplist-value配置的时候,采用ziplist作为列表的内部实现来减少内存使用
2)当ziplist无法满足条件的时候,会采用linkedlist作为列表的内部实现(双向列表的格式实现,但是链表的复杂空间过高,每个节点的内存都是单独分配的,会加剧内存碎片化影响内存的管理效率)
注:
Ziplist的实现方式:
通过给每个节点添加length属性实现,是为了节约内存开发的,由一些列特殊编码的连续内存块组成的顺序型数据结构。

Quicklist是zipList和linkedList的混合体,每一个段使用zipList来紧凑存储,多个zipList之间使用双向指针串接起来。
常见命令
BLPOP:移除并获取列表的第一个元素
BRPOP:移除并获取列表的最后一个元素
LPOP:移除并获取列表的第一个元素
LPUSH:将一个或多个值插入到列表的头部
Set集合
是String类型的无序集合,集合内容是唯一的。
数据结构
整数集合
当集合对象的所有元素都是整数值,并且保存的元素数量小于512个时,使用整数集合。而且是有序的集合,通过二分查找来实现查询。
Hashtable
当不满足整数集合的条件的时候,使用hashtable进行处理
应用场景
Set集合的复杂度是O(1),支持集合内的增删改查,支持多个集合的交集、并集、差集操作。
1)标签应用,根据标签将数据进行拆分
2)独立IP,使用唯一性保证IP的独立性
常见命令
SADD:向集合中添加一个或多个元素
SADD KEY VALUE
SCARD:获取集合的成员数
ZSet有序集合
可以输入分值,对集合内容进行排序。Redis通过分数来为集合中的成员进行从小到大的排序。
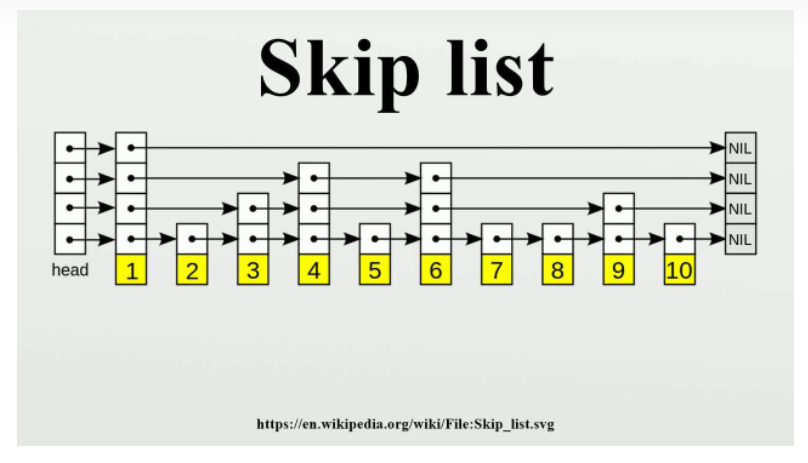
通过跳表,增加了数据查询的速度。基于单链表添加索引的方式实现,是以空间换时间的方式提升查询速度。
常见命令
zadd key score value
应用场景
用于排行榜成绩和带权重的消息队列
HyperLogLog
在误差范围内,对数据得基数(不重复元素的个数)进行统计(通过概率论的方式进行计算)。在输入元素的数量或者体积非常大的时候,计算基数所需的空间是固定,并且是很小的。每个键值只需要花费12KB内存,可以计算接近2的64次方个不同元素的基数。(只存个数,不存元素本身)。
数据结构
在输入元素的数量或者体积非常大时,计算基数所需要的空间总是固定、并且是很小的。通过桶结构(使用二进制数来代表)+稀疏矩阵的方式实现。
常见命令
PFADD:添加指定元素到HyperLogLog中
PFCOUNT:返回给定HyperLogLog的基数估算值
PFMERGE:将多个HyperLogLog合并为一个HyperLogLog
布隆过滤器
相对于Set集合的去重功能,布隆过滤器可以在空间上节省90%以上,但是有1%左右的误判率。
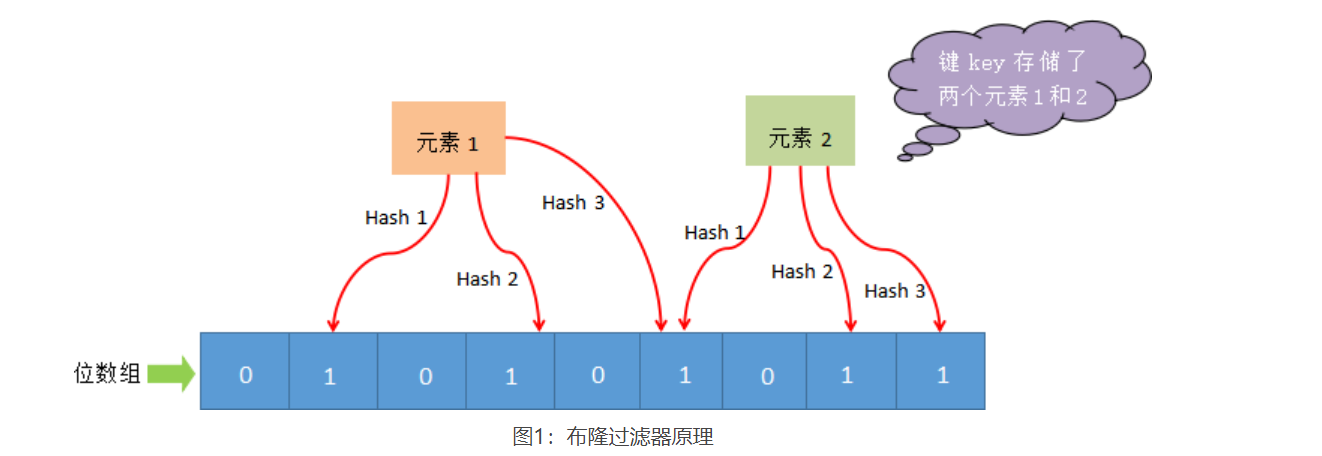
通过多次哈希值进行了判断,如果哈希对应的key值都是标记为1,则说明元素存在。
地理位置
主要用来存储地理位置信息,并对存储的信息进行操作
1.8.1.常见命令
GEOADD:添加地理位置
GEOPOS: 从给定的key里返回所有指定名称的位置
GETODIST:用于返回两个给定位置之间的距离