在Java中常见的数据结构在实际应用中很广泛,熟知常见的数据结构的应用对程序的效率会有较大的提升,应该是需要熟知和了解的。前段时间刚好也重新整理回顾过一些数据结构的基础知识,结合当前Java中的实际应用进行回顾和总结。在本章中主要是分析常见数据结构的使用场景和性能情况。
常见结构
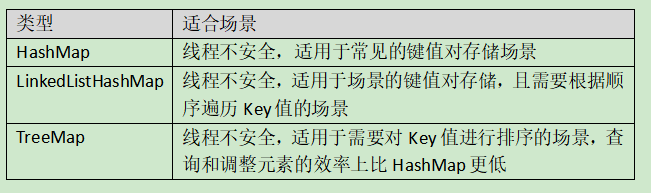
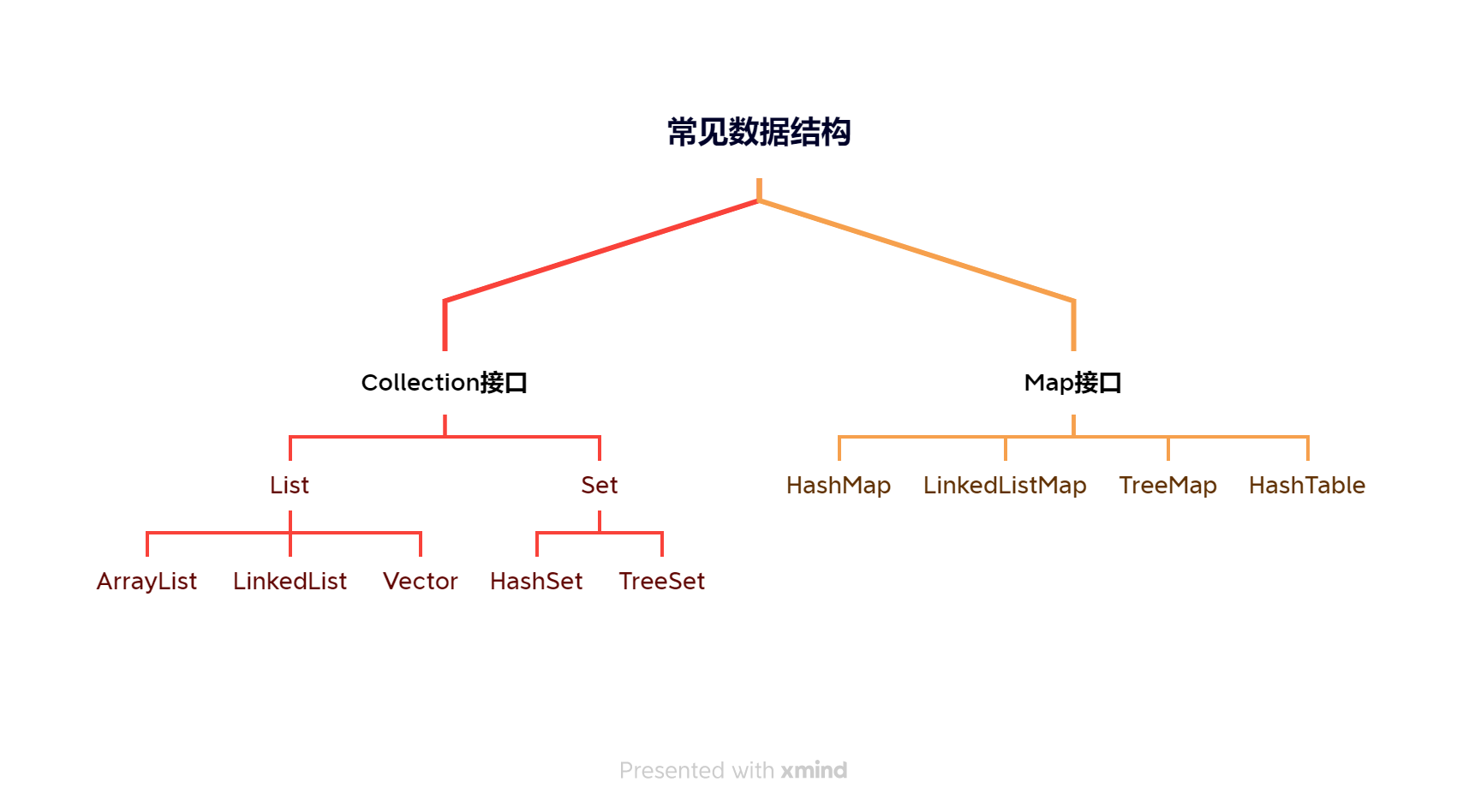
常见的数据结构主要分为实现Collection(集合)接口,和Map(键值对)接口两种类型的结构(中间层和互相的继承关系省略)。如下图所示
List类型结构
主要分为向量型(数组类型ArrayList)和列表型(链表类型LinkedList)。两者的实际数据结构可以参考如下:
数组类型

初始化情况:
默认情况下ArrayList的初始大小是10个,当容量超过10个的时候,会将整个数组的容量扩大为原来的1.5倍再进行赋值。因为该方式并不会涉及到时间复杂度很高的操作,所以数组扩容所消耗的时间可以不用计算在内。
访问情况:
由于数据是连续的,根据下表我们可以很容易定位到数据的位置,访问某一特定的位置仅需o(1)的时间复杂度。
修改情况:
替换:
和访问情况相同,修改时,我们仅需查找到需要访问的数据位置,然后进行替换即可,和查找的复杂度一眼,时间复杂度也为o(1)。
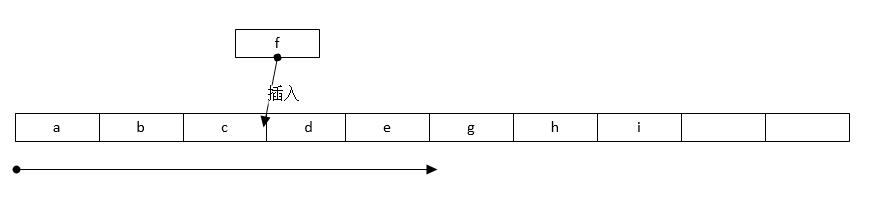
增加和删除:
此时应将d和后续所在位置的数组开始往后移动,此时调整的时间复杂度为o(n),删除同理
链表类型
链表类的地址不是连续的,通过指针(在Java中是对象引用的方式)来连接元素(双向链表)。

初始化情况:
链表通过指针的方式连接,初始化无需指定数组容量
查找情况:
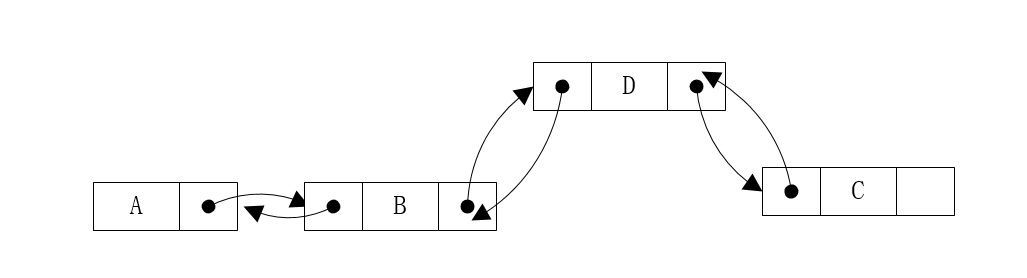
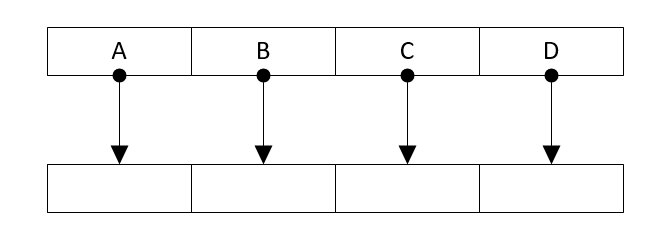
例如,查找上图中的元素C,需要从A查找下一个对象B,再查找至C。在最坏的情况下需要遍历整个链表,时间复杂度为O(n)
插入删除情况:
如在BC之间插入节点D,当定位到B节点时,仅需要改变B和C的对象引用关系,即可在常数时间内完成D节点的插入
Vector类型
Vector类型本质上是数组类型,是线程安全的,意味着每次调整List结构时,都会通过加锁的方式保障线程安全。这样访问的速度上会带来一定的损耗。
综上,每种数据结构有适合的场景

Set类型结构
Set类型结构和List结构的区别在于存储的是唯一值,元素不可重复
HashSet类型
该结构提供了常数时间的增删改查复杂度,并对存入的数据进行了唯一性的处理,如在结构中添加了a,b,c,d,d,则实际上保存的数据为a,b,c,d。
结构是非线程安全,也不能保证元素是有序的。该数据结构的底层是通过HashMap的方式实现的,通过唯一的key值的方式确定。
如图所示,当访问元素Key时,根据元素的哈希可以直接找到对应的元素,所以调整删除等操作复杂度都为常数级别。
TreeSet类型
基于TreeMap实现的Set结构,可以实现排序比较的Set结构,TreeMap基于红黑树结构(具体见Map结构的比较),在插入调整元素时候的效率不如HashSet,需要调整平衡二叉树上的节点。

Map类型结构
Map为Key,Value类型的数据结构,可以通过Key值找到对应的Value编码值。
HashMap类型
该数据结构采用散列表的方式实现,但是当桶的元素太多时,会将结构转换为类似TreeMap的结构(图片转载)
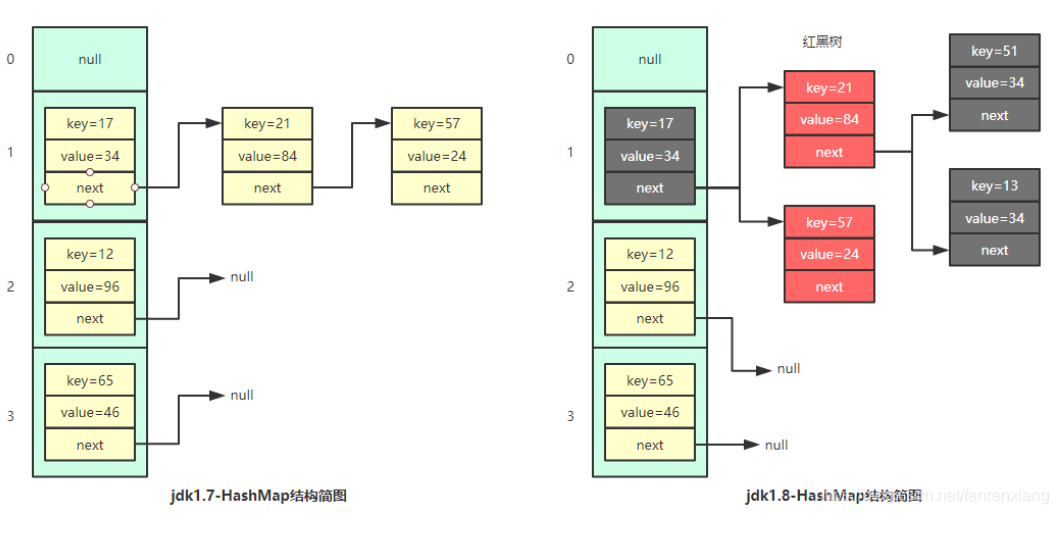
在JDK1.8中,在链表冲突达到8以上时,HashMap的结构转为红黑树后,查找效率将由o(n)变为o(logN)。如果设计良好的哈希编码可以避免大量的哈希值冲突,避免形成红黑树的结构。
LinkedListHashMap类型
和HashMap相比,LinkedListHashMap另外维护了一个链表,通过该方式可以顺序的查找关键字,但是和TreeMap相比没有实现排序功能。
TreeMap类型
和HashMap的实现上还是有区别,实现Key值排序的Map类型,是基于红黑树实现的。
结构类似如下图:
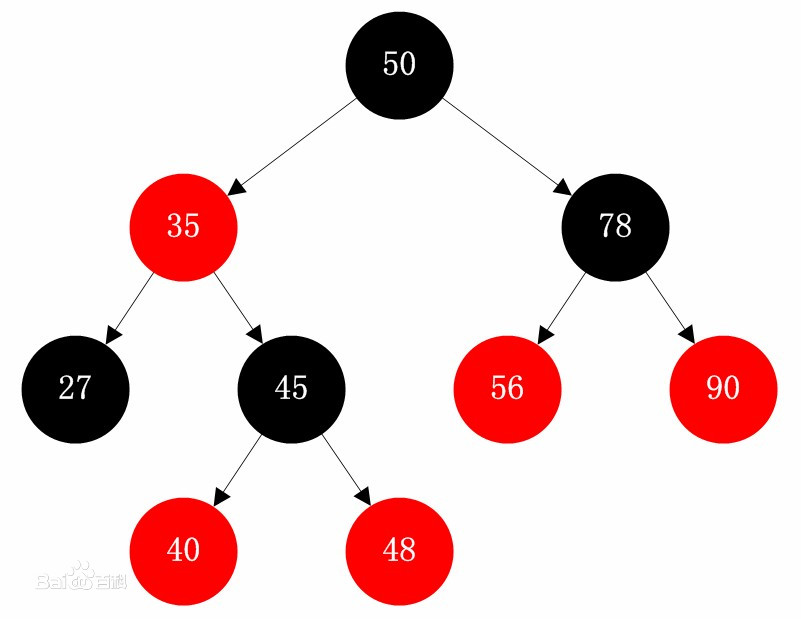
红黑树是一棵平衡二叉搜索树,和其他平衡二叉树的区别在于,在树进行平衡时,减少了二叉平衡树的翻转复杂度,可以在常数级别的时间内反转而成。但是区别于散列表结构,它的查询空间复杂度为O(longN),所以相比于HashMap效率更低。
HashTable类型
和HashMap的使用类似,但是是线程安全的,且哈希冲突后使用封闭定址的独立链法构建数据结构。查询的效率相比于HashMap更低。